The Troubleshooting Chart Process
July 9, 2014 by James WingIn an earlier post, I introduced The Troubleshooting Chart, and how building such a chart can help you troubleshoot an issue, communicate the status, and monitor the success of a fix. I'll explain more about the how the chart supports a structured and thorough troubleshooting process in this post.
Basic Troubleshooting Processes
The most basic troubleshooting processes usually consist of actions that organized support teams use to filter issues:
- Ask the customer to try it again, to see if the problem is repeatable
- Do basic knee-jerk troubleshooting, regardless of the issue. Reboot the machine, restart the service, refresh the browser, etc.
- Check for obvious error messages
- Check for matching knowledge base or incident records
Similar steps are used almost everywhere because they work a surprising percentage of the time. It filters issues from a large set of minor reports down to a distilled set of interesting problems. But what do you do when issues persist, and error messages don't tell you what to do? I have found opinions split here, between "follow a formal process" and "every issue is unique."
Formal Processes
Formal incident management processes attempt to address this through proscribed sequences of steps. There are a number of documented processes in this area, such as the currently popular ITIL Incident Management and Problem Management processes. These processes come complete with documented steps, flow charts, certification programs, and vendors prepared to sell you compatible tools. In dense text and flowcharts, they instruct you to perform a sequence of steps to resolve an issue, which mostly boil down to the following activities:
- Triage
- Determine Root Cause
- Fix
- Communicate Status
All the steps seem sensible and nutritious, and we probably want to cover them at some point. But they don't really convey actionable advice to humans. What exactly does Triage consist of? How exactly might we determine root cause? And is the defined, sequential ordering realistic in the confusion and panic of a serious incident?
Every Issue is Unique?
I'm not satisfied with simply deciding that hard issues are unique and require a completely one-off troubleshooting process. There is some truth to the uniqueness claim, but after handling many issues I certainly believe there is a core of repeatable activities. The formal process isn't wrong about that, they just try too hard to hold onto rigid process flows and sequences.
Troubleshooting Chart to the Rescue!
The Troubleshooting Chart can help by providing a concrete activity a human can DO in the service of these conceptual steps. Here's how:
Triage
The act of first preparing the chart involves many of the Triage activities. You will try to understand the customer complaint and confirm or deny their report based on system data evidence.
- Analyze the Complaint - Why did the customer complain now? What was the triggering event? Does system data confirm their report?
- Find 100% of Failure - Is the impairment total or partial? Do any other customers share this problem? For which attributes is the impairment 100%? For example, the same problem might be described as 5% of all reports failing, or 100% of a certain type of report for 3 customers is failing. Knowing what constitutes 100% of failure means you know what the impact is and what the fix must accomplish. Knowing "some reports are failing" doesn't cover it.
- Establish the Timeline - Based on the system data, what is the timeline of the incident? This may be different from when the first customer reported it, especially if the incident involves multiple features or customers.
Determine Root Cause
Even after a crude first pass at drawing the chart, you have some information about the impact and at least some parts of the timeline. This information will go a long way towards figuring out the root cause. The impact at least gives you a general subject, if not an exact feature or code module. That typically helps find error logs, activity data, and pointers to the technical experts that can help investigate further. Across many applications, technologies, and business models, constructing a timeline is the single most helpful activity in searching for a root cause. Most incidents result from a change to a previously stable system, and identifying when the change was introduced is frequently enough to identify what the change was. Although this model does not magically get us to 'why?' for every system, the timeline and impact information can be used to validate prospective root cause theories.
Fix
Although drawing the chart won't help you actually make the fix, it will be invaluable for assessing the success or failure of the fix and proving that the fix did indeed resolve the issues. And that the issues stay resolved. Unfortunately, there can be fixes that make the errors go away without restoring successful functionality. And temporary fixes that relapse shortly after victory is declared. So watch the success rate carefully, and check back on severe issues.
Communication
Severe incidents require a lot of communication early and often. The Troubleshooting Chart can help communicate the existence and status of an issue at various stages:
- Sharing what is known about existence and impact of an issue with the reporting customers, partners, or support staff and getting their feedback.
- Describing the incident to technical experts who can help with root cause determination. Updating non-technical team members and managers about what is going on. Success rate and time are pretty widely understood.
- Confirming the effectiveness of a fix, and declaring victory amongst your team.
- Analyzing the incident after the fact, in post-mortem or retrospectives held for serious incidents.
I would visualize these activities superimposed on the Troubleshooting Chart roughly as follows.
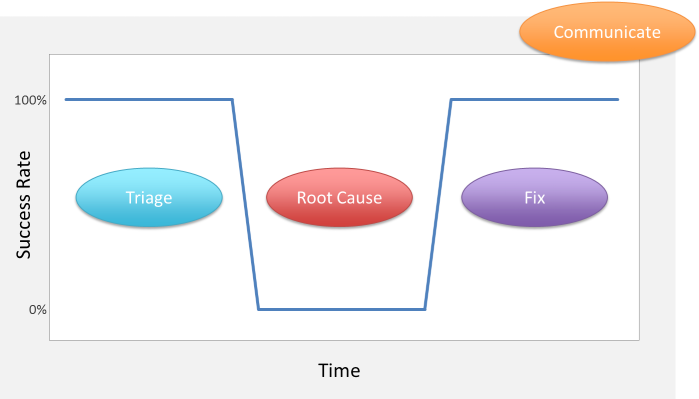
Hopefully, by now I've sold you on the Troubleshooting Chart as an important part of a healthy troubleshooting process. Next time, we'll look into the importance of tracking success rate versus error rates.
You might also enjoy:
- Introducing the Troubleshooting Chart
- Structured Troubleshooting Process
- Data Gathering and Processing