I was recently building a NiFi Flow for CloudTrail events that enriched the events with IP geolocation data, then wrote them to an S3 bucket to query with Athena. But I wondered, is it possible to use Athena to query CloudTrail records directly from S3 without reprocessing them?
The answer is yes, as long as some tortured SQL syntax doesn't bother you.
CloudTrail Event Format
CloudTrail events are written to files in your bucket in batches shortly after they are reported.
Each file contains a JSON object, with a single attribute, a Records array of individual events.
{
"Records":[
{
"eventVersion":"1.03",
"eventTime":"2016-01-01T00:00:04Z",
"eventSource":"monitoring.amazonaws.com",
"eventName":"PutMetricAlarm",
"awsRegion":"us-east-1",
...
{
"eventVersion":"1.03",
"eventTime":"2016-01-01T00:00:01Z",
"eventSource":"monitoring.amazonaws.com",
"eventName":"DescribeAlarms",
"awsRegion":"us-east-1",
...
},
...
]
}The CloudTrail events have many common fields like time, service, basic description, and user credential info. Additionally, each service logs their own combination of variable fields depending on the activity. JSON is a good format for flexibility in reporting fields.
Athena Table for CloudTrail
It's not too hard to set up an Athena table for CloudTrail events in their natural format. First, we need an Athena database:
CREATE DATABASE cloudtrail;Then we create a table. The following is a very simplified Athena table for some common fields:
CREATE EXTERNAL TABLE cloudtrail.events (
Records ARRAY<
STRUCT<
eventVersion: string,
eventID: string,
eventType: string,
eventTime: string,
eventSource: string,
eventName: string,
awsRegion: string,
sourceIPAddress: string,
userAgent: string,
userIdentity: STRUCT<
type: string,
arn: string,
principalId: string,
accountId: string,
userName: string
>
>
>
)
ROW FORMAT SERDE 'org.apache.hive.hcatalog.data.JsonSerDe'
LOCATION 's3://some-log-bucket/CloudTrail-trail1/AWSLogs/123456789012/CloudTrail/us-east-1/';This is an imperfect table, to be sure, as you can see with a simple query:
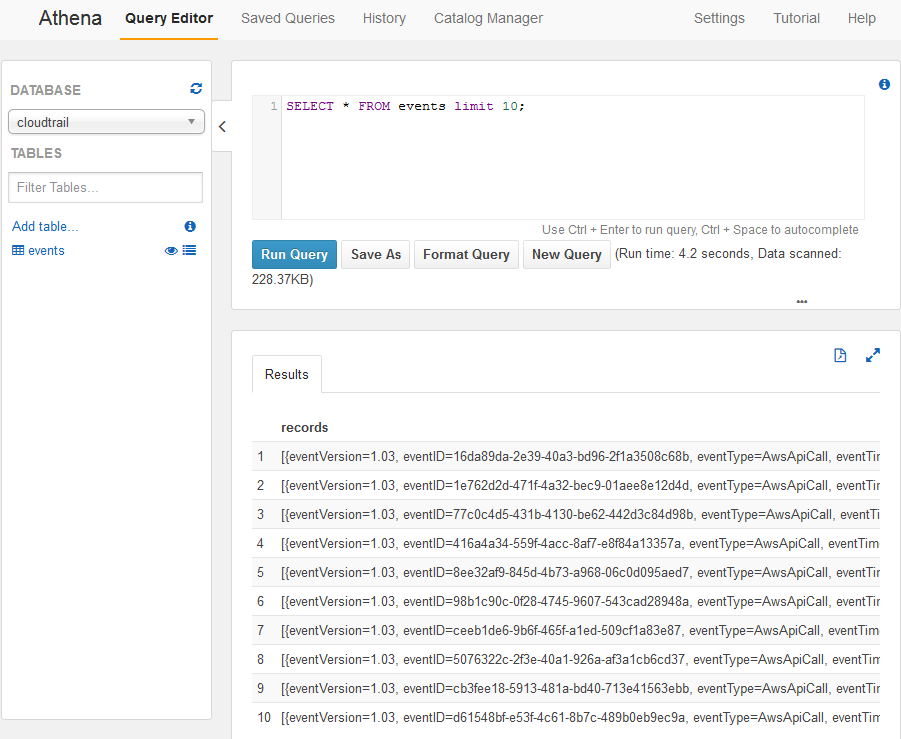
Each row in the table is indeed an array of "records". Useful. How do we get the events?
The following common table expression (CTE) uses the un-nest feature of Presto to get event rows out of our records arrays.
WITH events AS (
SELECT
event.eventVersion,
event.eventID,
event.eventTime,
event.eventType,
event.eventSource,
event.awsRegion,
event.sourceIPAddress,
event.userAgent,
event.userIdentity.type AS userType,
event.userIdentity.arn AS userArn,
event.userIdentity.principalId as userPrincipalId,
event.userIdentity.accountId as userAccountId,
event.userIdentity.userName as userName
FROM scratch.cloudtrail
CROSS JOIN UNNEST (Records) AS r (event)
)
SELECT * FROM events LIMIT 10;And then this gives us events on rows with columns for the event fields we are interested in.
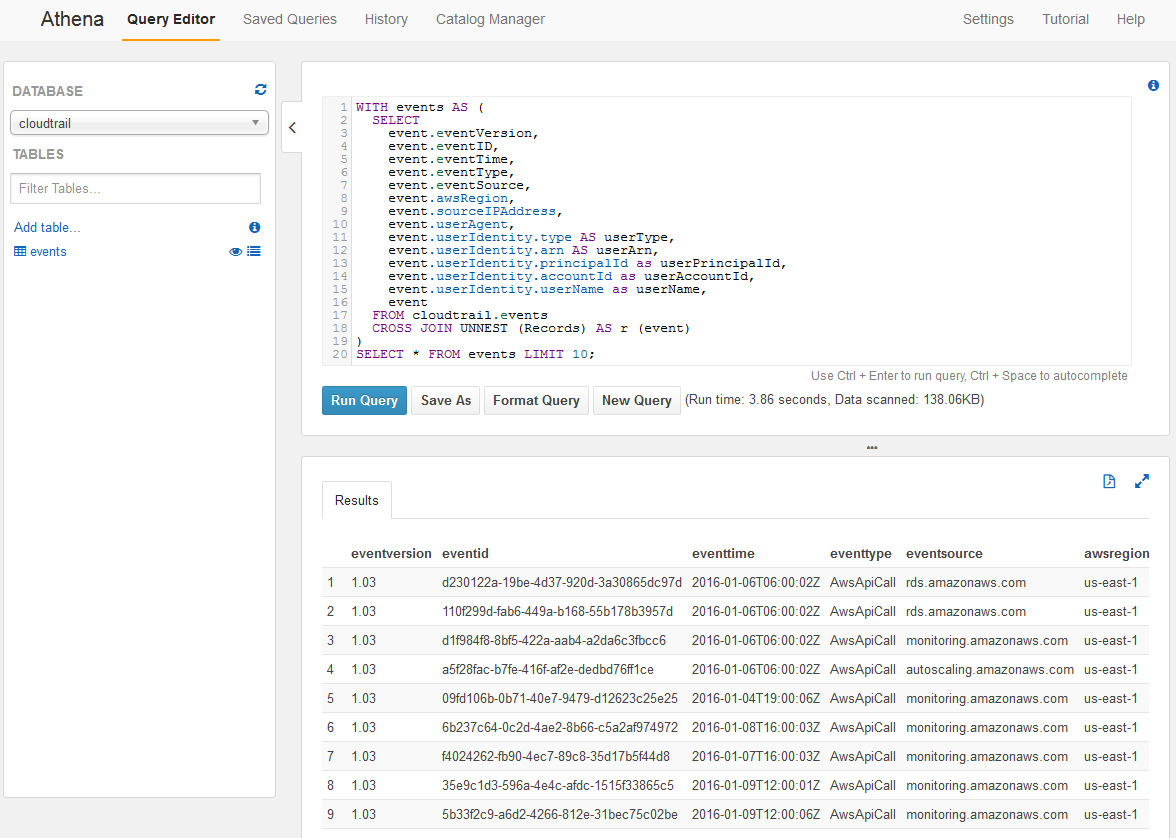
The last line of the query, SELECT * FROM events LIMIT 10, can certainly be replaced with any arbitrary query you wish to make.
Although the syntax is a bit clumsy, it does allow us to query the CloudTrail files without transforming them first. However, there are a number of other good reasons to process the CloudTrail events first, like the event enrichment discussed in the NiFi geolocation example.

